
저번 장에서 HTTP가 어떤것인지 대략적으로 살펴 보았습니다.
이번 장부터는 HTTP에 대해 본격적으로 공부하는 시간을 가지겠습니다.
URL은 과연 무엇일까요?
인터넷의 리소스입니다. 엄밀히 따지면 리소스를 위치를 통해 검색하는 것을 말하지만...
어차피 리소스를 찾는다는건 결국 리소스이기때문에 URL은 리소스라고 이해 해도 큰 문제는 없을 겁니다.
다만 URL자체 리소스라는 얘기는 아닙니다. 결과론적으로 리소스라는
얘기지...
아무튼 이번장에서 학습할 내용들은 다음과 같습니다.
1. URL 문법, 여러 URL 컴포넌트가 어떤 의미를 가지며 무엇을 수행하는지
2. 여러 웹클라이언트가 지원하는 상대 URL과 확장 URL 같은 단축 URL에 대해서
3. URL의 인코딩과 문자 규칙
4. 여러 인터넷 정보 시스템에 적용되는 공통 URL 스킴.
5. 기존 이름은 유지하면서, 객체들이 다른 장소로 옮기는 것이 가능하게 해주는 URN을 포함한
URL의 미래

우리는 URL을 통해서 정보를 공유할 수 있다.
다음은 어썸 데브 블로그라는 웹페이지다.
어썸데브블로그
주간 인기 블로그 게시글
awesome-devblog.netlify.app
이곳을 들어가보면 다양한 블로그글들을 확인 할 수 있다.
어떻게 수십개가 넘는 글들을 넣을 수 있엇던 걸까?
더욱 놀라운 사실은 이 글들의 소유자는 전부 다르다.
때로는 서버가 다른 경우도 있다. 이 경우에는 모든 글이 서버가 다르다고 말하기는 어렵지만, 아무튼 소유자는 전부 다르다.
신기하지 않은가?
간단히 URL하나면 어느곳에서도 접근이 가능하다.
이것이 바로 URL다.
그런데 URL이 있기전은 어땠을까?
파일을 공유해야 된 경우도 있을지도 모른다.
그럴때 사용되는 프로토콜이 ftp인데
ftp를 사용하려면 사용자들은 어느정도 네트워크를 알아야한다.
파일을 전달하기 위해서는 이 파일을 쪼개고 합치는 작업을 거쳐야 한다.
쪼개는 이유는 빨리 전달하기 위함이다. (자세한건 공부하시길...)
아무래도 10kg을 옮기는 것 보다 1kg을 10명이 옮기는 것이 더 빠르기 때문이다.
아무튼, 이러한 작업은 네트워크 환경에서 이뤄지며 이 작업은 ftp라는 프로토콜이 담당한다.
그러면 파일을 공유하기 위해서는 다음과 같은 작업을 거쳐야 한다.
ftp.joes-hardware.com에 FTP로 접속하고
익명 사용자로 로그인한다음,
비밀번호로 네 이름을 입력해
그리고 나서 pub디렉토리로 이동한뒤, 바이너리 형식으로 전환해
이제 complete-catalog.xml이라는 파일을 내려 받아.
이렇게 해야 한다. 끔찍하다.
그냥 ftp://ftp.lots-o-books.com/pub/complete-catalog.xml로 접속해 하면 위 작업은 할필요가 없다.
만약, 이렇게 복잡하면, 어쩔 수 없이 지금보다 네트워크 환경에 노출되어서 네트워크 지식이 자연스럽게 쌓일 수도 있겠지만,
개발자가 아닌 일반적인 사용자가 위 지식을 알 필요가 있을까?
아마 URL이 존재하지 않는다면 웹은 개발자의 점유물일것이고,
이렇게 까지 웹이 발전할 수 도 없을 것이다.
URL의 등장으로 모든이가 http자체를 공부할 필요는 없겠지만,
우리는 개발자, 그것도 웹 개발자이기 때문에
URL을 공부하면 더 좋지 않을까?
URL 문법
놀라운 사실은 스킴이 달라질때마다 문법이 조금씩 달라진다고 한다.
그렇다고 해서 다이나믹 하게 문법이 바뀌지 않고 서로 유사하다고 하며,
대부분 일반 URL 문법을 따른다고 한다.
일반적인 문법은 다음과 같다.
<스킴>://사용자 이름:<비밀번호>@<호스트>:<포트>/<경로>;<파라미터>?<질의>#<프레그먼트>스킴
근데 스킴이라는 건 무엇일까?
스킴은 스키마라고 하며, 주어진 리소스에 어떻게 접근하는지 알려주는 중요한 정보라고 한다.
이는 URL을 해석하는 애플리케이션(웹이라던지... 뭐 그런거)이 어떤 프로토콜의 리소스를 사용해야 하는지 알려준다.
그러니까 굳이 http가 아니여도 된다는 뜻이다.
근데 생각해보면 모든 프로토콜이 가능한 것일까? 그것까지는 잘모르겠는데...
아마 대부분은 가능할지 않을까?
Uniform Resource Identifier (URI) Schemes
info Information Assets with Identifiers in Public Namespaces. [RFC4452] (section 3) defines an "info" registry of public namespaces, which is maintained by NISO and can be accessed from [http://info-uri.info/]. Permanent - [RFC4452]
www.iana.org
이건 스킴에 사용되는 프로토콜을 정리?해놓은 글이다.
정확히 전송계층만 사용한다. 애플리케이션 계층만 사용한다고 단정지을 수는 없겠지만,
하나 확실한 것은 스킴으로 사용할 수 있는 프로토콜은 꾸준히 증가하고 있는 것 같다.
특히한 점은 크롬 확장자(chrome-extension)와 비트코인(bitcoin)이 존재한것으로 봐서 이 친구들도 url을 통해 리소스가 전달되는 사실을 알게 되었다.
조사하면서 알게 된 사실인데 IANA라는 인터넷 할당 번호 관리기관에서 IP, 최상위 도메인등을 관리하는 것으로 봐서
IANA - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전.
ko.wikipedia.org
이곳에서 허락?받은 프토콜만 URL의 스킴으로 인정받는게 하는 추측을 해본다.
이제는 ICANN에서 관리한다는데..
포트 - 해시넷
포트(port)란 컴퓨터끼리 정보를 교환하기 위해 사용하는 가상의 논리적 접속 위치이다. 널리 알려진 포트 번호에는 20번(FTP), 22번(SSH), 23번(telnet), 25번(SMTP), 53번(DNS), 80번(http), 110번(POP3), 143번(IMAP)
wiki.hash.kr
포트는 현재 국제 인터넷 주소 관리기구(ICANN)이 인터넷 할당 번호 관리기관(IANA)를 통하여 포트 번호를 할당하고 있다.
결국 국제 인터넷 주소 관리기기인 ICANN에서 인터넷 할당 번호 관리 기관 IANA를 통해서 관리 된다는 것을 알 수 있다.
다른것도 많은데 너무 스킴만 말한것 같군요.
이제 9개중 1개 했습니다. 갈길이 멀군요.
호스트와 포트
애플리케이션이 인터넷에 있는 리소스를 찾으려면, 리소스를 호스팅하고 있는 장비와 그 장비 내에서 리소스를 접근할 수 있는 서버가 어딘지 알아야 한다라고 한다.
일반적으로 url은 이렇게 작성합니다.
www.naver.com:80 일부러 스킴없이 했는데없어도 연결이 되네요.
보통은 이렇게 작성이 되어지는데 이게 무엇일까? (사실 포트는 생략하는게 일반적이지만 설명을 위해 추가함)
생각을 해봐야 한다.
리소스를 호스팅하고 있는 장비는 www. naver. com을 뜻하는 것 같구
그 장비 내에서 리소스를 접근할 수 있는 서버는 80 서버 즉, http서버를 사용하고 있다는 것을 짐작할 수 있다.
참고로 http는 내부적으로 tcp 프로토콜을 사용한다고 하는군요.
어차피 http는 전송 프로토콜이 아니니까 더 특화된 tcp에 손을 벌리는게 맞는거지만요.
여기서 알 수 있는 사실은 navar라는 곳에서 www. naver. com이라는 리소스를 호스팅하고 있다는 사실을 알 수 있습니다.
근데 생각해봅시다.
리소스를 호스팅하는 방법이 주소값으로 작성하는 방법밖에 없을까요?
애초에 위 주소는 ip주소를 통해 만들어집니다. dns.. 네 추후에 공부할 수 있겠지만 이걸로 변환 시켜줍니다.
네이버는 보여주는 ip주소가 2개군요.
또한 주소가 www. naver. com이 전부가 아니라는 사실도 알게 되었습니다.
www.naver.com.nheos.com 이게 이름이구
223.130.195.200 이게 위 리소스의 ip값입니다.
223.130.195.95 도 있습니다.
이걸로 접속을 해도 정상적으로 접속이 된다는 사실을 알 수 있다.
정확히 잘 모르겠지만...
리소스를 호스팅하고 있는 장비라는 건
네트워크어딘가에 등록되있는 곳이라 생각이 되어집니다.
현실세계로 따진다면 이건
정확한 위치라고 할 수 있을 것 같습니다.
예를들면, 지하철이라던지, 도서관이라던지 뭐 그런...
얘네의 위치를 찾아가려면 주소를 보고 이동할 수 도 있겠지만, 우편 번호를 보고도 충분히 그 장소를 찾아갈 수 있죠.
다만 우편번호로 길을 찾는건 어렵다는게 함정이지만요.
이론상 가능하다는 얘깁니다.
이제 호스팅을 하고 있는 장비에 대해 얘기 해봤는데,
그 장비내에서 리소스를 접근을 할 수 있는 서버에 대해 얘기해봅시다.
이건 어떤 스킴이냐에 따라 달라지는 것 같습니다.
왜냐하면 이것은 포트번호를 뜻하기 때문이죠.
포트라는건 하나만 존재하지는 않습니다.
물론, 하나만 존재할 수도 있겠지만...
현실에서도 어떤 도착지에 가기 위해 걷기도 하고, 뛰기도 하고, 택시를 탈 수 있으며, 비행기도 탈 서 이동할 수 있습니다.
때로는 다른 길로 갈수도 있죠.
이말은 단 하나의 방법만 존재하는 것은 절대아니라는 얘기죠.
나는 이렇게 가고 싶은데...
단 한가지 방법만 존재한다면 그렇게 가야 합니다.
물론, 도착지에 정상적으로 도착 하면 다행이지만, 그 과정이 굉장히 비효율적일 수도 있고,
도착을 못한다면... 그 포트는 사용해서는 안됩니다.
왜냐하면 일을 못했거든요.
그러면 그 포트를 사용하는 의미가 없다고 생각합니다.
결국 포트로 나누는 것은 보다 효율적으로 길을 찾기 위함이라고 생각합니다.
그 장비 내에서 리소스를 접근할 수 있는 서버가 포트인건 알겠는데..
개발자가 아닌 일반 사용자가 포트번호를 기억하면서 작성하기는 쉽지 않습니다.
만약, 포트번호를 무조건 작성을 해야한다면 너무 괴로울 것 같습니다.
다행스럽게도 생략이 가능하다는 군요. 다행이네요. (스킴으로 확인 할 수 있어서 그런가...)
사용자 이름과 비밀번호
때로는 서버에서 자신이 가지고 있는 데이터에 접근을 허용하기 전에 사용자 이름과 비밀번호를 요구할 때가 있다.
가장 좋은 서버는 ftp서버다.
만약에 특정한 누군가에게 파일을 전달 하고 싶다면...
이것을 지정할 필요는 있지 않을까?
솔직히 다른거에 비해 이곳은 그리 비중이 있는것 같지 않다.
다만 그렇다고 무시해서는 안된다. 왜냐하면 이것이 필요할때가 반드시 존재하기 때문이다.
아무튼
형식은 다음과 같다.
사용자 이름:비밀번호@호스트:포트이렇게 구성된다고 한다.
참고로 기본 사용자 : anonymus일 경우
인터넷 익스프로는 IEUser, 크롬은 chrome@exmaple.com이 기본 값이라고 한다.
경로
드디어 나왔습니다. 경로입니다. 아까 네이버를 예시로 들었죠.
저는 솔직히 www. naver. com이 경로라 생각했죠.
하지만 아니라는 군요.
다음음
section.blog.naver.com/BlogHome.nhn
네이버 블로그의 서버와 경로를 작성했습니다.
URL 경로의 가장큰 특징은 파일 시스템 경로와 유사한 구조를 가진다고 합니다.
추후에 학습하게 될 파라미터, 쿼리랑 비교하면서 공부하면 더 좋을 것 같군요.
잠깐 다른 얘기를 해봅시다.
저는 스프링 부트로 개발하고 있습니다.(따지고 보면 얘도 스프링)
스프링에는 pathParameter라는것이 존재하는데 이것은 특정 패턴을 이용해서 경로를 지정해줍니다.
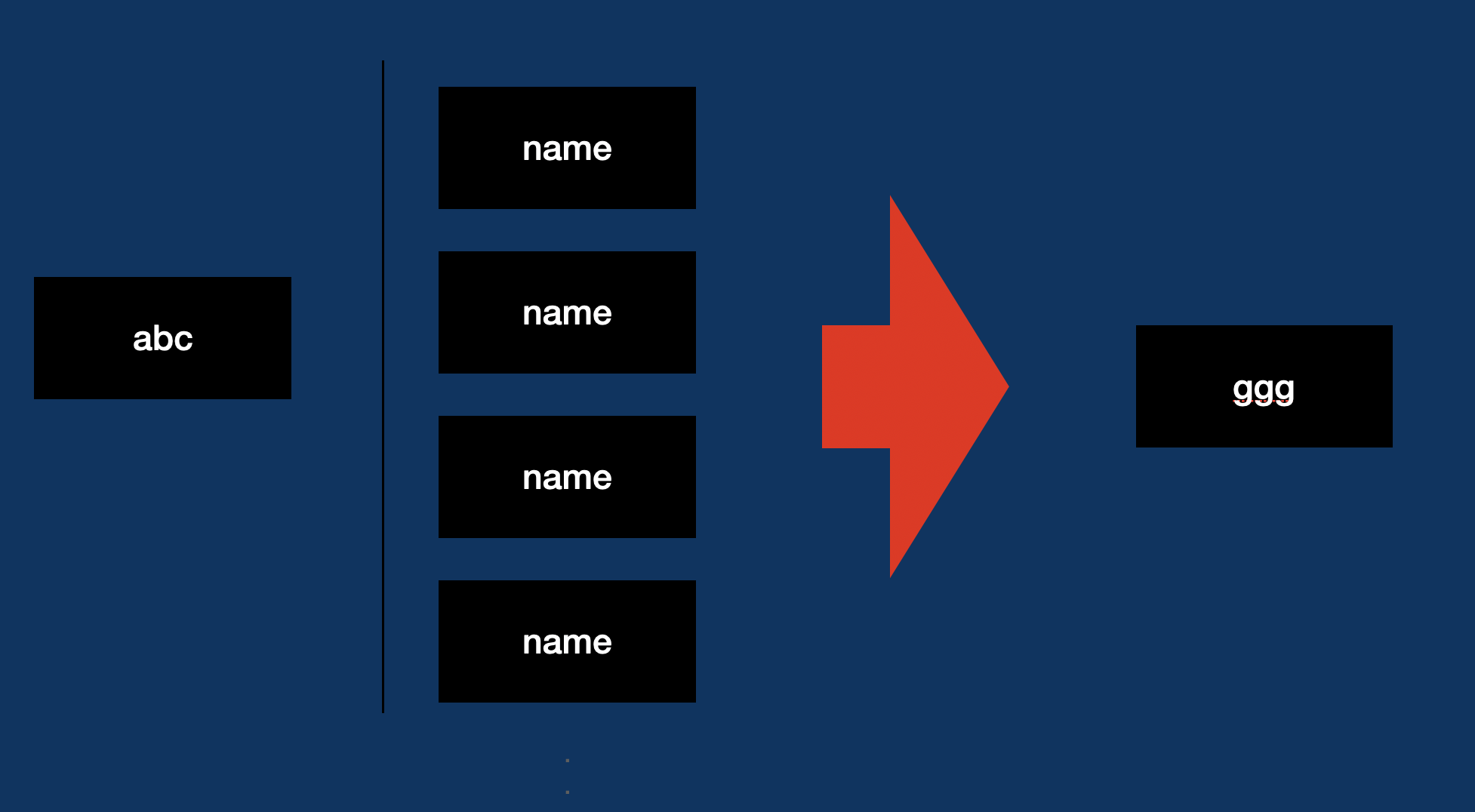
만약에
www.aaa.co.kr/abc/{name}/ggg 이렇게 나오면
이렇게 해석 할 수 있을 것 같습니다.
www.aaa.co.kr이라는 서버가 존재하는데
경로는 abc -> {name} -> ggg순으로 이동할 수 임을 의미하는 것 같습니다.
경로를 지정했다는건 그곳으로 갈 수 있음을 의미하는데...
그림을 그려봅시다.
앞으로 url을 만들때 이것이 경로로서의 의미가 있는지 생각해봐야 할것 같습니다.
아무거나 경로로(pathvariable) 만드는것은 그리 좋은 습관은 아닌것 같습니다.
파라미터
많은 스킴이 객체에 대한 호스트 및 경로 정보 만으로는 리소스를 찾지 못한다.
URL의 파라미터 컴포넌트는, 애플리케이션의 서버에 정확한 요청을 하기 위해 필요한 입력 파리미터를 받는데 사용한다.
이름 / 값 쌍으로 구성되며 URL 나머지 부분들로 부터 ;문자로 구분하여 작성되어진다고 한다.
책에서는 결국 에플리케이션이 리소스에 접근하는데 필요한 어떤 추가 정보든지 전달 할 수 있다고 합니다.
일반적으로 추후에 학습할 질의 문자열과 함께 사용하는것 같은데...
;이것을 사용되어지는 경우는 전역적으로 적용하기 위함이 아닐까 유추해본다.
질의 문자열
데이터베이스 같은 서비스로 부터 요청을 받는 리소스 형식으로 범위를 좁히기 위해 질문이나 질의를 받을 수 있다.
위에서 경로를 학습했다.
생각해보면 이거랑 유사한다.
차이점이 있다면 질의 문자열은 경로가 아니다.
마치 짜장면 먹을래? 짬뽕먹을래? 처럼 답이 정해지는 상황에서 사용하면 좋을 것 같다.
짬뽕이냐 짜장면에 따라 경로를 구분할 필요는 없다.
그냥 물어보면된다. 경로를 나눈다는 건 짬뽕과 짜장면을 먹는곳이 달라야 한다는 이야기와 다르지 않는다.
위 그림을 다시 소환해보자.

만약에 name을 통해 abc에 적용해서 ggg로 이동 되어진다면 이렇게 다시 작성되는게 더 효율적이다.
abc?name="뭘까?"/ggg 이것을 그려보면

이렇게 그려질 것이다.
추가적인 질의 문자열을 추가하려면 &를 이용하면 된다고 한다.
생각해보면 경로를 나눈다는건 URL입장에서 자원을 소모한다는 의미니까..
질의 문자열보다는 경로를 나누는것이 더 효율적이라 생각이 든다.
각자 맞는 역할에 맞게 작성하는것이 제일 좋은 거라 생각한다.
프레그먼트
프레그먼트는 위 방식들보다 더 작게 나눌때 사용되어진다.
이거는 같은 페이지내에서 구분이 할때 사용한다.
그러니까 내가 URL문법에 대해 설명하면서 커다란 글씨로 남기면서 작성하고 있다.
이게 클릭이 되는지는 잘모르겠지만...
만약 클릭이 된다고 한다면, 다른 사용자에게 이 부분만 똑 때서 공유할 수 있다.
설명이 장황한것 같은데... 한번 보는게 좋을 것 같다.
Mockito - mockito-core 3.10.0 javadoc
Latest version of org.mockito:mockito-core https://javadoc.io/doc/org.mockito/mockito-core Current version 3.10.0 https://javadoc.io/doc/org.mockito/mockito-core/3.10.0 package-list path (used for javadoc generation -link option) https://javadoc.io/doc/org
javadoc.io
이곳은 모키토 document다. 이게 뭘 설명하는지는 중요하지 않고,
내려가면서 커다란 제목을 누르면 주소창에 #이 추가된것을 확인 할 수 있다.
만약에 내가 Making sure interaction(s) never happened on mock라는것을 공유하고 싶다면
이것을 누른뒤
https://javadoc.io/doc/org.mockito/mockito-core/latest/org/mockito/Mockito.html#never_verification
이렇게 공유하면 된다. 이제 이곳을 들어가면 아까 언급한 곳이 가장 눈에 들어온다.
이게 바로 프레그먼트다.
단축 URL
요즘 브라우저들은 사용자가 기억하고 있는 URL일부를 입력하면 나머지를 자동으로 입력해주는 URL'자동 확장 기능'을 제공합니다.
또, 리소스 안에 있는 리소스를 간결하게 기술하는데 사용하는 상대URL을 제공한다고 합니다.
이들에 대해 조금더 자세히 공부해봅시다.
상대URL
지금까지 학습한 URL은 절대URL이라고 한다. 그러니까 URL에 모든 정보가 담겨있다는 뜻이다.
하지만 상대 URL은 모든 정보를 담지 않고 base정보를 이용해서 다른 리소스에 접근을 해야한다고 한다.
솔직히 어떻게 설명을 해야하는지 감이 잡히지는 않지만.... 일단 해보자.
적다보면 이해가 될지도 모르기 때문이다.
이게 상대 경로랑 같은 것 같다.
애초에 상대 URL이 가능하기 위해서는 base url이 필요하다.
그러니까 기준이 필요하다는 이야기다.

그림을 보면 3번째를 기준으로 잡았다.
이것을 0번이라고 하자. 왼쪽은 -1씩 증가하고 오른쪽은 1씩 증가한다고 하자.
어쩌면 이거랑 개념은 비슷하다고 생각한다.
다만 다른 점은 상대 경로에는 방향 개념이 없다는 점이 가장 크다.
일반적으로 현재 위치는 ./으로 작성하고 ../ 이전 위치로 작성되어진다.
그러니까 ./을 작성할때는 현재 위치는 같지만 다른 파일? 리소스?를 이용할때 사용이 되어지고
../은 이전 위치에서 검색할때 사용되어진다.
책에서는 다음과 같이 설명하고 있다.
기준이 되는 URL이 : http://www.joes-hardware.com/tools.html이라고 하고
상대 URL이 : ./hammers.html이라고 한다면...
harmmers.html을 검색할때는
http://www.joes-hardware.com/harmmers.html
이렇게 검색이 되어진다고 한다.
아 알겠다. 나는 URL 그러니까 주소창에서 이걸 어떻게 작성하는지에 대해 고민을 했었다면,
사실은 그게 아니라 html을 작성할때 상대URL을 작성할 수 있다는 것 같다.
URL을 처리하는 브라우저 같은 애플리케이션은 상대 URL간에 상호 변환을 할 수 있어야 한다.
상대 URL을 사용하면, 리소스 집합을 쉽게 변경할 수 있다. 그리고 문서 집합의 위치를 변경하더라도,
새로운 기저 URL에 의해서 해석될 것이기 때문에 위치를 변경하더라도 잘 동작할 것이다.
이는 마치 다른 서버에 있는 콘텐츠를 미러링 할 수 있게 허용하는 것 과 유사하다.
URL 확장
이것은 브라우저의 기능인것 같다.
예를들어 naver이라고 브라우저에 검색을 하게 되면
www와 com을 붙여준다.
어떻게 보면 조금더 빠르게 검색이 가능하게 해주는 것 같다.
확장에는 호스트 확장과 히스토리 확장이 존재하는데,
호스트 확장같은 경우 위에서 언급한 방식이구
히스토리 확장은 이전 히스토리를 브라우저가 미리 제시해주는 것을 말한다.
브라우저 확장 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 확장 프로그램(Extension) 또는 웹 브라우저 기능 확장 프로그램 또는 확장 기능은 웹 브라우저의 기존 기능의 동작을 변경하거나 완전히 새로운 기능을 추가하는
ko.wikipedia.org
URL 확장은 다른 말로 브라우저 확장이라고도 한다.
솔직히 URL확장 보다는 브라우저 확장이 더 와닿는 것 같다.
브라우저는 이런 간단한 기능을 제공하여 사용자의 절약을 혼란을 막아준다.
하지만 호스트 명에 대한 기능은 프락시와 같은 HTTP 애플리케이션에 문제를 발생 시킬 수 있다.
프락시를 사용하는 경우 URL 자동확장 기능은 다르게 동작할 수 있다고 한다.
이 내용은 추후 더 자세히 배운다고 한다.
안전하지 않은 문자
URL은 인터넷에 있는 모든 리소스가 여러 프로토콜을 통해서 전달될 수 있도록, 각 리소스에 유일한 이름을 지을 수 있게 설계되었다.
어떤 프로토콜을 이용하던지 안전하게 전송하는것을 중요시 했다.
여기서 안전한 전송이란?
정보의 유실 없이 전송됨을 의미한다. 예를들어 SMTP같은 경우 특정 문자를 제거할 수 있는 전송 방식을 채택하고 있다.
간이 우편 전송 프로토콜 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 간이 전자 우편 전송 프로토콜(Simple Mail Transfer Protocol, SMTP)은 인터넷에서 이메일을 보내기 위해 이용되는 프로토콜이다. 사용하는 TCP 포트번호는 25번이다. 상
ko.wikipedia.org
위키백과를 확인해보면 모든 문자가 7bit로 되어어야 한다고 한다.
그러니까 8비트가 넘어가는 순간 정보는 유실된다는 의미다.
왜 7bit냐고? 한다면 잘 모르겠다.
아스키 코드 - 나무위키
IBM CP437 아스키 코드에는 제어 문자 자리에 Null(0x00)을 제외한 32개의 특수문자를 배당해 놓았다. 물론 그렇다고 해서 제어 문자의 기능이 없어지는 것은 아니며, 프로그램이나 글꼴에 따라서는
namu.wiki
이걸 보면서 확신을 가졌다.
smtp는 정보교환용 7bit 부호 체계인 아스키 코드로 만들어졌다는 것을 알 수 있다.
그러면 한글같은 경우는 어떻게 되고, 첨부파일이 추가되면 비트가 늘어나게 됨으로 유실이 무조건 발생할 수 밖에 없다.
이를 8bit를 7bit로 변환하든, MIME을 사용하든 해야 하는것 같다.
사실 여기에서 중요한건 SMTP를 사용하게 되면 정보가 유실될 수 있는데 URL에서는 어떻게 안전하게 전송할지가 중요하다.
(SMTP에 대한 이야기는 나중에 정리하는것이 좋을 것 같다.)
또한, URL 설계자들은 안전하게 전송되는것도 중요했지만, 가독성도 중요하다고 생각했다.
그래서 출력이 되지 않거나 보이지 않는 문자들은 사용이 금지되었다.
근데 사람들이 URL에 이진 데이터나 일반적으로 안전한 알파벳 외의 문자도 포함하고 싶다는 것을 알게 되었다고 한다.
어떻게 하면 안전하지 않는 문자들을 안전한 문자로 만들 수 있을까?
대표적인 예로 이스케이프를 들 수 있다. 이스케이프 문자를 쉽게 표현하면 띄어쓰기다. (엄밀히 따지면 아니지만....)
띄어쓰기 같은 경우는 위에서 말했듯이 안전한 문자가 아니다. 따라서 사용이 불가능하다.
URL 문자 집합
초창기 URL은 US-ASCII형식으로 되있었다. 그러다 보니 되지 않는 기능이 굉장히 많았다.
대표적으로 위에서 언급한 이스케이프가 있다.
US-ASCII에는 이스케이프가 금지되어있었다.
과거에는 상관없던것들이 현대에 들어서는 이것이 문제가 되기 시작했다.
왜냐하면 이 문자 집합으로는 한계가 존재하기 때문이다. 공백이 되지 않는것은 당연하고
라틴계열의 문자나 한글은 사용할 수 없었다.
다행히 지금은 이러한 것들이 지원되고 있다.
따라서 URL의 이동성과 완성도를 높였다는 것을 알 수 있다.
인코딩 체계
그러면 어떻게 이스케이프 문자를 추가할 수 있던것일까?
유니코드를 직접적으로 사용한것두 아니구...
(아스키를 사용해서 뒤집지 않는 이상 불가능하겠지만...)
바로 %와 16진수 두 문자를 활용해서 이스케이프 또는 URL에서는 사용이 금지 된 문자를 사용할 수 있게 되었다.
또한 몇몇 문자들은 US-ASCII에 포함되어 있지 않거나, 인터넷 게이트 웨이와 프로토콜에서 혼동되는 것으로 알려져 있어 사용이 꺼려 진다고 한다.
다음은 인코딩 체계표다.
HTML URL Encoding Reference
HTML URL Encoding Reference URL - Uniform Resource Locator Web browsers request pages from web servers by using a URL. The URL is the address of a web page, like: https://www.w3schools.com. URL Encoding (Percent Encoding) URL encoding converts characters i
www.w3schools.com
퍼센트 인코딩 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 퍼센트 인코딩(percent-encoding)은 URL에 문자를 표현하는 문자 인코딩 방법이다. 이 방법에 따르면 알파벳이나 숫자 등 몇몇 문자를 제외한 값은 옥텟 단위로 묶어
ko.wikipedia.org
유튜브를 생각해보자.
유튜브는 유튜브 + / 사용자 명으로 검색을 하게 되면 다음과 같이 들어 갈 수 있다는 것을 알 수 있다.
https://www.youtube.com/백기선
백기선
백기선(a.k.a, Whiteship)의 프로그래밍
www.youtube.com
위 URL같은 경우는 입력 URL이기 때문에 한글이 나오지만,
실제로 한글은 안전하지 않는 문자다. 따라서 다음처럼 인코딩 되어진다.
https://www.youtube.com/%EB%B0%B1%EA%B8%B0%EC%84%A0
근데
https://www.youtube.com/~백기선
이렇게 검색 해도 같은 결과가 출력이 되어진다.
그래서 ~문자는 인코딩이 되어지는지 확인해봤다.
https://www.youtube.com/~%EB%B0%B1%EA%B8%B0%EC%84%A0
놀랍게도 ~는 인코딩이 되지 않았다.
책을 읽어보니 ~는 ASCII코드 126(0x7E)이다.
그러니까 ~도 인코딩이 되어지면
%7E%EB%B0%B1%EA%B8%B0%EC%84%A0 이렇게 인코딩이 되어지는게 맞다.
왜 %을 붙이냐면 위에서 설명했듯이 URL에서는 US-ASCII를 사용하고 있기 때문에 일부 문자는 사용이 불가능하다.
따라서 16진수로 인코딩한 결과를 %에 붙여서 인코딩하고 있다. 그러니까 %는 그 문자를 인코딩한다는 의미로 받아드리면 된다.
그러면 위 상태로 검색해보자.
놀랍게도 검색이 되어진것을 알 수 있다.
https://www.youtube.com/%7E%EB%B0%B1%EA%B8%B0%EC%84%A0
지금 보면 유튜브는 ~가 인코딩이 되어있지 않고 있다.
이게 문제가 되지 않을 가능성이 크지만, 책에서는 이것을 인코딩하지 않은 애플리케이션 개발자의 실수라고 한다.
뭐 유튜브에서 저걸 했으니 이유는 있겠지...
아무튼 내가 말하고 싶은건 유튜브 개발자가 실수 했다는 게 아니라
책에서 나온 내용이 이렇다는 것이다.
책에서는 극단적인 방법을 소개하는데 그건 모든 문자를 인코딩하는 방법을 소개한다. 다만 안전한 문자들을 인코딩하지 않는 애플리케이션도 있기 때문에 오동작을 일으킬 수 있다고 한다.
http말고 다른 스킴들도 존재한다.
https, mailto, ftp, rtsp, rtspu, file, news, telnet등이 있다. (이 부분은 추후에 정리할 것 같다.)
URN
현재 URL의 가장 큰 문제점은 리소스의 위치가 변경이 되면 찾을 수 없다는 점이다.
일단 위치가 변경이 되면이라는 뜻을 이해야 되는데,
간단하게 생각해서 naver에 존재하는 정보는 tistory에서는 찾을 수 없음을 의미한다.
물론, naver같은 경우 검색 포털이기 때문에 찾을 수 있겠지만,
만약, 검색 포털이 아니라면....
검색이 불가능해지고 상태코드:404가 발생하게 된다.
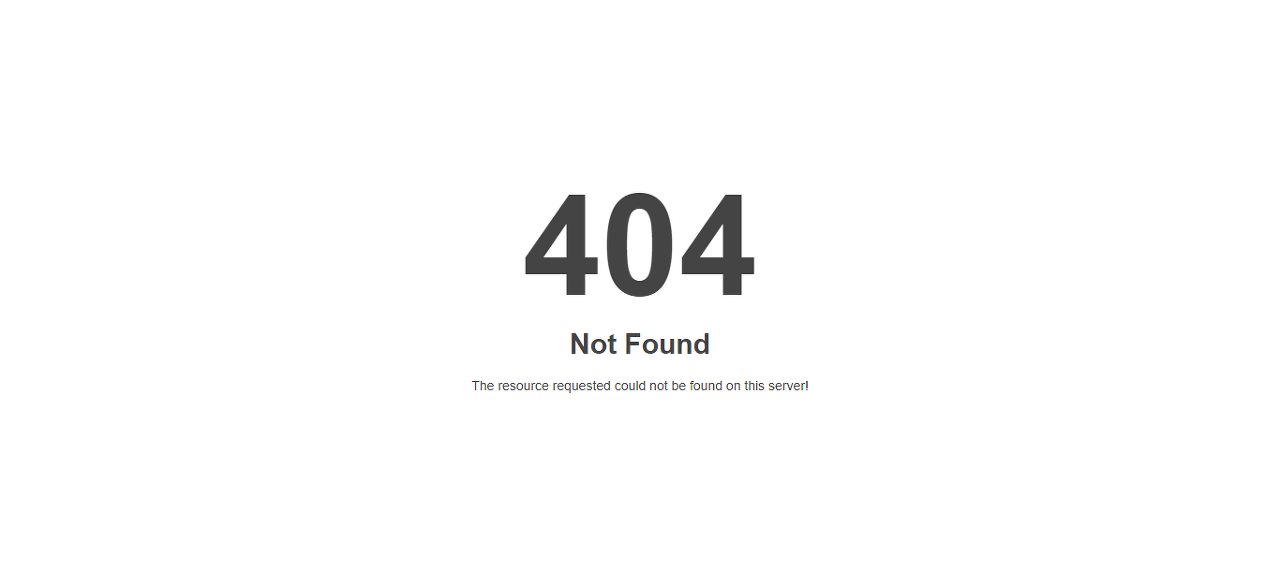
어떻게 보면 어떤 특정한 리소스를 찾기 위해 URL이라는 주소체계를 사용하는 것인데...
그러니까 특정 리소스를 찾기 위해서는 URL이라는 주소가 필요한데..
사람 부르는 것처럼 그 리소스를 바로 호출해서 사용할 수는 없을까?
이렇게 해서 나온것이 바로 URN이다.
그러니까 이 블로그가 b-programmer이라는 이름을 가지고 있는데...
이게 어디서든지 검색이 가능해진다는 이야기가 된다. 결국 주소를 작성하지 않고
b-programmer로 불러서 호출이 가능해진다는 이야기다.
근데 생각해보면 URL을 사용하기 때문에 네이버나 구글같은 검색 포털이 생겨난것이 아닐까 추측한다.
만약, URN이 활성화가 된다면 검색 포털은 사라질까?
잘모르겠다.
리소스의 이름으로 불러서 리소스를 호출하는 것은 좋은데...
그 이름을 포장하려고 덕지덕지 붙여지지 않을까 생각이 든다.
왜냐하면 김철수라는 이름을 가진 사람이 있다고 가정하자.
그러면 그 이름을 가진 사람은 한명이 아닐것이다. 즉, 동명이인도 존재할지도 모른다는 이야기다.
결국 어느 지역에 사는지, 무슨 김씨인지 이렇게 들어가면 그 김철수는 단 한명일것이다.
물론, 이렇게 해서 특정한 리소스위한 이름을 찾으면 다행이지만, 못찾으면 어떻게 될까?
즉, 너무 길어지면 어떻게 할까?
만약, URN이 상용화된다고 해도 URL은 사라지지는 않을 것 같다.
때로는 리소스를 찾기 위해 주소를 확인할 필요가 있기 때문이다.
언젠가 URN이 사용할 수 있게 되는 그날을 기약하며...
추가정보
https://www.w3.org/Addressing/
https://datatracker.ietf.org/doc/html/rfc1738
https://datatracker.ietf.org/doc/html/rfc2396
https://datatracker.ietf.org/doc/html/rfc2141
https://datatracker.ietf.org/doc/html/rfc3986
https://archive.org/services/purl/
https://datatracker.ietf.org/doc/html/rfc1808