어떤 방법으로 성능 개선하는것이 좋을까?
- 개발/읽기 성능 개선
- 2025. 8. 15. 01:46
TD;DR
읽기 성능을 해결할 수 있는 여러 방법들중에 어떤 방법을 선택해야 효과적일까요?
상품 데이터 100만건, 브랜드 10만건으로 테스트를 진행해볼 예정입니다.
2.87s에서 5ms으로 성능 개선한 과정을 작성해놨습니다.
어마무시시한 성능개선은 다음과 같이 진행을 하였습니다...* 이미지는 변경될 수 있습니다.

데이터 세팅
데이터는
상품 100만건
브랜드 10만건
나머지는 최대한 중복이 되지 않게 설게 되어질 예정이다.
이렇게 진행할 예정이다.
기존에는 브랜드 4건, 100만건을 비교해봤지만
생각보다 브랜드 쪽에 4건을 인덱스로 걸어봤지만 엄청난 효과를 보지 못하였다.
실험 결과는 그대로 남길 예정이며,
최종 결과에는 반영이 되어지지 않을 예정이다.기존 테스트 url: https://b-programmer.tistory.com/461
기존 테스트에서는
브랜드 4개 vs 브랜드 100만개 성능 비교, totalCount를 캐싱했을때가 적혀있습니다.
진행 과정
진행과정은 다음과 같다.
1. 데이터 세팅
2. 인덱스 실험 (브랜드 ID, 좋아요, 타 칼럼, 단일, 복합)
2.1 explain
2.2 k6 성능 측정 (UV: 10)
3. 반 정규화 테스트
3.1 explain
3.2 k6 성능 측정 (UV: 10)
4. 캐싱 처리
4.1 좋아요 순위 top 10 캐싱 k6 성능 측정 (UV:10)
기존 테스트에서는 UV를 1로 설정하였다.
- 추가적인 테스트가 진행하지 않을 목록
1. 브랜드 4건 vs 100만건 추가
2. totalCount 캐싱 처리
이들은 실험 과정만 남겨놓을 예정이다. 최종 비교에는 빠질예정이니 참고 부탁드립니다.
조회하는 방법에는 여러가지 방법이 있다.
1. DB를 직접적으로 조회하는 방법
2. API를 사용하는 방법..
3. k6로 UV를 설정해서 조회
나의 실험 쿼리는 다음과 같다.
SELECT
p.id,
p.brand_id,
b.name,
p.name,
p.price,
p.description,
ps.like_count
FROM product p
inner join brand b
on p.brand_id = b.id
inner join stock s
on p.id = s.product_id
inner join product_status ps
on p.id = ps.product_id
order by ps.like_count desc
limit 0,10데이터를 세팅해보고
explain으로 실행계획을 실행 해보았다.

요렇게 나왔다.
각 칼럼의 특징을 말해보면 다음과 같다.
key는 사용된 인덱스 명
type은 접근 방식 (index, range, ALL)
- index: 인덱스에 저장된 순서대로 모든 행을 읽는 경우.
ALL보다는 빠르지만 여전히 모든 인덱스 행을 읽기 때문에 비효율적일 수 있습니다.- range: 인덱스된 컬럼을 사용해 특정 범위(BETWEEN, <, >)의 행을 찾는 경우
- All: 테이블에 있는 모든 행을 처음부터 끝까지 스캔하는 경우
- eq_ref: JOIN에서 PRIMARY KEY나 UNIQUE KEY를 사용해 다른 테이블의 특정 행을 찾는 경우. 제공해주신 이미지의 3행에 해당하며, 조인에서 매우 효율적인 방식
rows는 예측된 스캔 행수를 뜻한다.
Extra는 추가정보를 말하며 index / Using filesort 여부라고 한다.
index - 인덱스를 사용하는 경우
Using filesort - 인덱스를 사용하지 않고 정렬를 사용하는 경우
마지막으로
filtered는 필터를 거친 뒤 남은 데이터 개수 라고한다.
rows = 10000
filtered = 5
→ 실제로 조건을 만족한 건 10000 × 0.05 = 500건
사전 준비는 이전정도로 하고 분석해보면
이걸로 알 수 있는 사실은 PK로 되어있는곳이 아니라면 매우 비효율적이라는 걸 알 수가 있다.
아마 PK도 인덱스니 그런걸까...
특히, stock, prdocut_satate의 예측 스캔수가 99만이 된다. 이는 엄청난 성능이 감소가 된것을 확인 할 수가 있다.
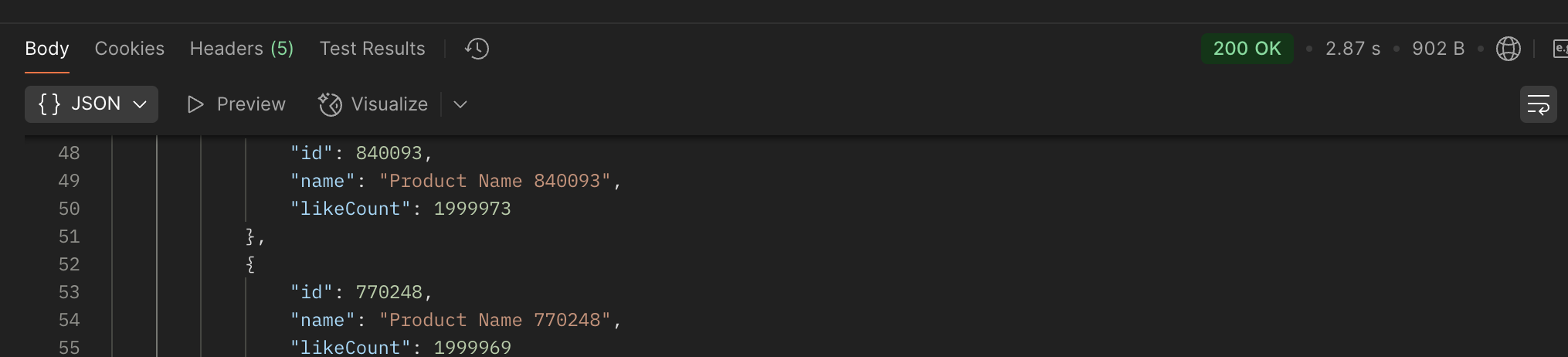
생각보다 시간이 오래 걸렸다. 2.87초나 걸렸다.
분명히 페이징을 사용했는데...
k6를 사용했을때 다음과 같은 결과를 도출 할 수 있었다.
█ TOTAL RESULTS
checks_total.......................: 60 0.899572/s
checks_succeeded...................: 100.00% 60 out of 60
checks_failed......................: 0.00% 0 out of 60
✓ status is 200
HTTP
http_req_duration.......................................................: avg=10.01s min=6.18s med=9.9s max=11.78s p(90)=11.67s p(95)=11.7s
{ expected_response:true }............................................: avg=10.01s min=6.18s med=9.9s max=11.78s p(90)=11.67s p(95)=11.7s
http_req_failed.........................................................: 0.00% 0 out of 60
http_reqs...............................................................: 60 0.899572/s
EXECUTION
iteration_duration......................................................: avg=11.01s min=7.18s med=10.9s max=12.78s p(90)=12.67s p(95)=12.7s
iterations..............................................................: 60 0.899572/s
vus.....................................................................: 9 min=9 max=10
vus_max.................................................................: 10 min=10 max=10
NETWORK
data_received...........................................................: 52 kB 777 B/s
data_sent...............................................................: 8.2 kB 123 B/s
평균 : 10.01초가 걸렸다. 100만건을 조회하는데 10.01초가 걸려서 빠르다고 생각할 수 있다.
하지만 이건 페이징을 10개만 지정한 결과이기 때문에 느리다.
참고로 TPS는 0.9 정도가 나왔고, http_reqs가 tps라고 한다.
생각보다 빨라서 놀랬다. 하지만 이 값은 테스트 횟수가 적고, 10페이지를 조회하기 때문에 느린거라고 한다.
그렇다면 이것을 어떻게 해결 할 수 있을까?
1. 인덱스 적용
2. 비 정규화
3. 캐시 적용
을 통해서 이 문제를 해결 할 수 있다고 한다.
갑자기 궁금한점이 생겼다. 인덱스 적용만 했을때, 비 정규화만 했을때, 캐시만 적용했을 때를 각각 비교하면 어떤 결과를 도출 할 수 있을까? 각각 한번 실험해보자.
암튼 가장먼저 고민할건 인덱스 적용이다.
현재 내 쿼리는 join문을 사용해서 100만건이 되는 데이터를 세팅하고 있다.
테이블은 총 4개. brand, product, stock,product_status 이렇게 지정 되어있다.
이 쿼리에서 중심이 되는 테이블은 product다.
product를 활용해서 brand, stock, product_status가 조회가 되어진다.
어떤 칼럼이 조회가 되어지는지 살펴보면
product.id,
product.brandId,
brand.name,
product.name,
product.price,
product.description,
status.likeCount칼럼은 총 7개이며 현재, 유일하게 조회가 되지 않는 테이블은 stock이다.
~그럼에도 불구하고 추가했던 이유는 상품을 조회할때 재고도 확인 할 수 있어야 하지 않을까 해서 추가했던거 같다.
~칼럼을 정리해보면
브랜드id, 브랜드 명, 상품 ID, 상품명, 상품 가격, 상품 상세 소개, 좋아요 갯수, 상품 생성일, 상품 수정일
그렇다면 어디에 인덱스를 거는것이 좋을까?
테이블은
브랜드 : 상품 = 1 : N
상품 : 재고 = 1:1
상품 : 좋아요 = 1:1
이렇게 되어있다.
이 말을 다시 말하면 브랜드가 아무리갯수가 많아도, 상품보다는 적다는 뜻이고, 재고랑, 좋아요는 상품이랑 같다고 할 수 있다.
결국 브랜드 ID랑 브랜드 명은 인덱스에 거는 순위에서 밀리게 되는걸까? - 브랜드 ID는 상품쪽에 있는 브랜드 ID다.
일단 상품 ID는 pk가 걸려 있기 때문에 예외로 치고 나머지 8개에서 인덱싱을 걸어야 할거 같다.
어디다 거는게 좋을까?
내가 알기로는
카디널리티가 높은 곳에 인덱싱을 걸어야 하지만, 그렇다고 해서 모든곳에 인덱싱을 걸면, 오히려 성능 저하가 발생할 수 있을 수 도 있다고 한다.
인덱싱은 where절과 order절을 통해 인덱싱을 거는것을 최우선으로 고려 해봐야 할듯싶다.
현재의 카디널리티를 계산해보자.

맨처음은 prodduct_id로 pk라 인덱스로 지정할 필요가 없다 생각해 중요하다 생각하는 부분만 거져왔다.
물론 이걸 토대로 인덱스를 결정하는건 아니라 생각이 든다. 왜냐하면, 수치는 계속 변하기 때문에 저걸로 당장 판단 할 수 없다고 생각한다.
카디널리티(Cardinality)란, 컬럼에 존재하는 서로 다른(고유한) 값의 개수를 의미합니다.
단순하게 카디널리티가 높은것을 인덱스로 지정하면 안 된다고 생각한다. 왜냐하면, insert 혹은 update될때 마다 중복이 되지 않는 칼럼이 추가될 수 있기 때문이다. 좋아요 같은 경우는 초기에는 전부 0으로 고정이 되있지만, 시간이 지날 수록 중복 되지 않는.. 그러니까 고유한 값의 갯수가 늘어나기때문이다. 그렇다고 해서 이걸 예측하고 인덱스를 설정할 수 도 없다.
이거를 표를 통해 한번 유추해보자.
| productId | brandId | brandName | produdctName | productPrice | productDescription | productLikeCount |
| 1,000,000 | 99,988 | 99,888 | 1,000,000 | 690,416 | 1,000,000 | 736,452 |
| 1,000,000 | 99,990 | 99,990 | 1,000,000 | 690,497 | 1,000,000 | 736,315 |
| 1,000,000 | 99,997 | 99,997 | 1,000,000 | 690,528 | 1,000,000 | 736,261 |
| 1,000,000 | 99,989 | 99,989 | 1,000,000 | 690,658 | 1,000,000 | 735,266 |
| 1,000,000 | 99,990 | 99,990 | 1,00,000 | 690,112 | 1,000,000 | 735,875 |
현재는 7개의 칼럼만 존재하기 때문인데 사실 where에서만 사용되는거랑 order쪽에서만 사용되는것도 정리할 필요가 있을거 같다.
암튼 나는 랜덤 범위를 일부러
FLOOR(100 + RAND() * 2000000) * 100 AS price,200만으로 설정하였다. 그 이유는 너무 작게 설정하게 되면 항상 같은 숫자만 나와 계산하는 의미가 없다고 생각했다.
이렇게 5번의 시도를 하였는데 신기하게도 100만에 가까이 가는건 없었다.
인덱스 적용
브랜드 Id만 인덱스를 거는 경우는 어떨까? 생각보다 속도는 비슷하게 나오는듯하다.

요렇게 나왔는데 이건 안 거는거랑 비슷한거 같다라는 생각이 들었다.
그래서 좋아요를 기준으로 시도해보자.

좋아요를 하니 생각보다 빨라졌긴했지만 그렇다고해서 의미있는건지는 잘 모르겠다.

이걸 봐서는 성능이 개선이 되었다고는 말하기 어려울거같다. 우리가 주목해야하는건
바로
Using temporary; Using filesort요 부분인데 이것에 대한 뜻은 인덱스를 사용하지 않았다는 뜻이다.
찾아보니 다음과 같다라고 한다.
인덱스가 정렬에 사용되지 못한 이유
복합 인덱스 부재:
MySQL은 WHERE 절과 ORDER BY 절을 동시에 처리할 수 있는 복합 인덱스가 있으면 성능이 크게 향상됩니다.
(brand_id, like_count) 순서로 복합 인덱스를 만들면, brand_id = 1인 데이터를 찾으면서
동시에 like_count를 기준으로 정렬된 데이터를 얻을 수 있습니다.
WHERE 절과 ORDER BY 절의 컬럼 불일치: brand_id와 like_count는 서로 다른 테이블에 있습니다.
MySQL은 brand_id 인덱스를 사용해 데이터를 필터링한 후,
product_status 테이블에 접근하여 like_count를 가져오고, 그 결과를 다시 정렬해야 합니다.
이때 인덱스 없이 정렬하면 filesort가 발생합니다.
filesort의 원리: MySQL은 인덱스를 사용할 수 없을 때,
정렬에 필요한 데이터를 메모리(sort buffer)에 로드하여 정렬합니다.
데이터가 많아 메모리를 초과하면 디스크에 임시 파일을 만들어 정렬하는데, 이것이 filesort입니다.이거에 대한 해결책은 여러가지가 있는데
지금 당장 할 수 있는 해결책으로는 복합인덱스를 사용하는것이다.
이거에 대한 키는 product_id다. product_id는 두 테이블을 연결해주는 칼럼이기 때문에 각각 복합 인덱스로 만들 수 가 있다.
복합 인덱스로 설정하고 다시 설정해보자.

확실히 성능이 좋아졌다는것이 체감이 되어진다.
이제 k6를 사용해서 결과를 도출해보자.
█ TOTAL RESULTS
checks_total.......................: 80 1.196333/s
checks_succeeded...................: 100.00% 80 out of 80
checks_failed......................: 0.00% 0 out of 80
✓ status is 200
HTTP
http_req_duration.......................................................: avg=7.35s min=7.08s med=7.3s max=7.74s p(90)=7.74s p(95)=7.74s
{ expected_response:true }............................................: avg=7.35s min=7.08s med=7.3s max=7.74s p(90)=7.74s p(95)=7.74s
http_req_failed.........................................................: 0.00% 0 out of 80
http_reqs...............................................................: 80 1.196333/s
EXECUTION
iteration_duration......................................................: avg=8.35s min=8.08s med=8.3s max=8.74s p(90)=8.74s p(95)=8.74s
iterations..............................................................: 80 1.196333/s
vus.....................................................................: 10 min=10 max=10
vus_max.................................................................: 10 min=10 max=10
NETWORK
data_received...........................................................: 70 kB 1.0 kB/s
data_sent...............................................................: 11 kB 164 B/s확실히 이전 시간 보다
전반적으로 HTTP 요청 시간(평균)은 약 26.6%, 반복 소요 시간(평균)은 약 24.2% 단축되어 상당한 성능 향상이 있었음을 알 수 있습니다.이정도가 성능 향상이 되었다는 것을 알 수 가 있었다.
커버링 인덱스
아쉽게도 지금은 커버링 인덱스가 아니다. 왜냐하면 커버링 인덱스는 쿼리가 필요로 하는 모든 컬럼이 인덱스에 포함되어 있어, 데이터 테이블에 접근할 필요가 없을 때를 말한다. 결국 select절에 존재하는 친구들 때문에 커버링 인덱스라 알 수 가 없을거 같다.
SELECT p.id, ps.like_count
FROM product p
INNER JOIN product_status ps ON p.id = ps.product_id
WHERE p.brand_id = 1
ORDER BY ps.like_count DESC
LIMIT 0, 10;이런게 커버링 인덱스라고 한다. 현재 인덱스는
CREATE INDEX idx_brand_id_and_id ON product (brand_id, id);
CREATE INDEX idx_product_id_and_like_count ON product_status (product_id DESC, like_count DESC);이렇게 설정되어 있다.
그러면 인덱스로 설정하게 되면 무조건 성능이 좋아질까?
위에서 확인했듯이 잘 못사용하는 경우 성능 향상에는 아무런 영향이 없었다. 심한 경우에는 오히려 성능이 떨어질 수 도 있지 않을까?
인덱스를 설정할때 대분류 > 중분류 > 소분류를 통해 인덱스를 만들게 된다.
하지만 이렇게 만들게 되면, 대분류의 데이터가 적어 인덱스가 걸리지 않을 수 있다.
그럼에도 불구하고 이렇게 설정해야 하는 이유는 뭘까?
대분류부터 인덱스를 먼저 설정해야 하는 이유는
소분류에서 데이터가 많아지는 것보다
대분류에서 데이터가 많아지는 것이 더 치명적이라 생각한다.
인덱스는 단순히 '데이터를 빠르게 찾는 도구'를 넘어, '어떤 쿼리가 가장 많이 실행될 것인가' 를 예측하고 거기에 맞춰 최적화하는 전략적인 도구라 한다.
반 정규화
비 정규화,반 정규화로 불리며, 정규화된 내용을 반대로 하는 작업을 말한다.
정규화가 쓰기 성능에 사용이 되어진다면,
비 정규화는 읽기 성능에 사용이 되어진다.
테이블은 다음과 같다.
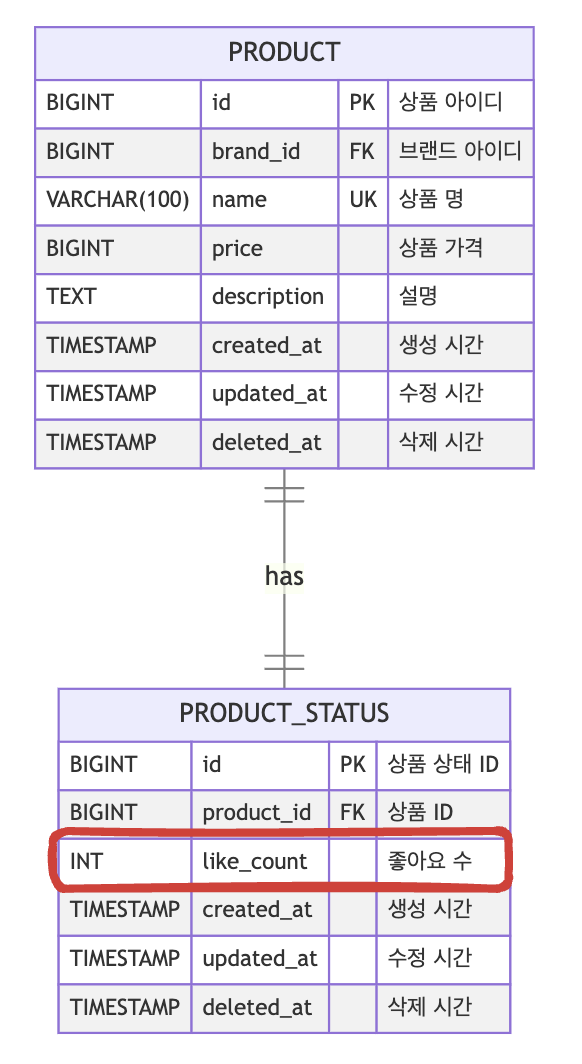
요게 기존 erd인데
만약, 반 정규화를 하게 되면 product_status의 like_count가 product로 들어가게 되어진다.
애초에 이렇게 설계를 한 이유는 상품과 상품 상태이 서로 update를 수행할때 영향이 없게끔하는것을 목적으로 하고 있다.
하지만, 각기 다른 테이블로 되어있기 때문에 읽기시에 join을 걸어서 데이터를 가져올 수 밖에 없다.
그리고 인덱스 파트에서 잠깐 나왔는데 서로 다른 테이블로 되어있기 때문에 하나의 인덱스로 묶어서 사용할 수는 없다.
그렇다면 어떻게 해야 할까?

요렇게 count를 product에 강제적으로 밀어넣는 방법이 있다.
당연히 이렇게 하면, join문을 걸지 않아도 되기때문에 상대적으로 빠르게 데이터를 가져올 수 있다고 생각한다.
또 인덱스도 인덱스 하나로 만들 수 가 있다.
즉, 우리는 트레이드 오프를 생각하지 않을 수 없다.
읽기 성능이냐 쓰기 성능이냐..
여기가 읽기 작업이 많은곳이라면 반 정규화가 유리할것이고
쓰기 작업이 많은곳이라면 정규화가 좋을것이다.
일단, 반 정규화를 했을때, 얼마나 성능이 향상이 될지 한번 테스트 해보자.
반정규화 + 인덱스는 추후에 작업할 예정이다.
자 이제 시작해보자.
SELECT
p.id,
p.brand_id,
b.name,
p.name,
p.price,
p.description,
p.like_count,
p.created_at,
p.updated_at
FROM product p
inner join brand b
on p.brand_id = b.id
inner join stock s
on p.id = s.product_id
order by p.like_count desc
limit 0,10;쿼리는 이렇게 변경이 되었다.
API를 돌렸을때 어떻게 나올까?
explain은 그렇게까지 머가 바뀐건 아니지만..

요렇게 나왔다.
생각보다 코드를 많이 바꾼거 같다.
다시 준비는 끝났으니 다시 실행해보자.
TOTAL RESULTS
checks_total.......................: 100 1.590844/s
checks_succeeded...................: 100.00% 100 out of 100
checks_failed......................: 0.00% 0 out of 100
✓ status is 200
HTTP
http_req_duration.......................................................: avg=5.28s min=5.18s med=5.22s max=5.81s p(90)=5.32s p(95)=5.81s
{ expected_response:true }............................................: avg=5.28s min=5.18s med=5.22s max=5.81s p(90)=5.32s p(95)=5.81s
http_req_failed.........................................................: 0.00% 0 out of 100
http_reqs...............................................................: 100 1.590844/s
EXECUTION
iteration_duration......................................................: avg=6.28s min=6.18s med=6.22s max=6.82s p(90)=6.32s p(95)=6.82s
iterations..............................................................: 100 1.590844/s
vus.....................................................................: 10 min=10 max=10
vus_max.................................................................: 10 min=10 max=10
NETWORK
data_received...........................................................: 87 kB 1.4 kB/s
data_sent...............................................................: 14 kB 218 B/s이걸 토대로 기존으로 돌렸을때와 비교해보자.
확인해보니 다음과 같다는 결과가 나왔다.
전체적으로 HTTP 요청 시간은 약 47~49%, 반복 소요 시간은 약 38~40% 단축되어 상당한 성능 개선이 이루어졌습니다.
흥미로운 결과인듯하다.
이걸로 봤을때 기존 > 반 정규화 > 인덱스 순으로 읽기 성능이 향상이 되었다는것을 알게 되었다.
만약, 반 정규화와 인덱스를 동시에 거는것이 좋을까?
음.. 잘 모르겠다. 반 정규화를 했을때, 성능이 좋지 않는 경우 더 고려해볼 수 있을거 같은데
지금 상황에서는 두 개다 성능이 나쁘지 않기 때문에 굳이 할필요는 없다 생각한다.
하지만 우리는 학습중이니 일단 진행시켜보자.


역시나 explain은 크게 변하지 않았다..
속도는 어떨까?
█ TOTAL RESULTS
checks_total.......................: 270 4.451973/s
checks_succeeded...................: 100.00% 270 out of 270
checks_failed......................: 0.00% 0 out of 270
✓ status is 200
HTTP
http_req_duration.......................................................: avg=1.24s min=1.18s med=1.22s max=1.4s p(90)=1.3s p(95)=1.32s
{ expected_response:true }............................................: avg=1.24s min=1.18s med=1.22s max=1.4s p(90)=1.3s p(95)=1.32s
http_req_failed.........................................................: 0.00% 0 out of 270
http_reqs...............................................................: 270 4.451973/s
EXECUTION
iteration_duration......................................................: avg=2.24s min=2.18s med=2.23s max=2.4s p(90)=2.3s p(95)=2.32s
iterations..............................................................: 270 4.451973/s
vus.....................................................................: 10 min=10 max=10
vus_max.................................................................: 10 min=10 max=10
NETWORK
data_received...........................................................: 234 kB 3.9 kB/s
data_sent...............................................................: 37 kB 610 B/s반복 소요 시간은 전체적으로 약 64~65% 감소하여 성능이 개선되었다.
그전 테스트 했을때와 비교헀을때 엄청난 효과였다..
캐시 적용
마지막으로 우리가 확인해야 하는 작업은 캐시를 적용하는것을 확인하면 된다.
일단 시작하기에 앞서 캐시가 어떤것인지 부터 생각해봐야 한다.
캐시를 한다는건 무거운 부분을 미리 데이터를 가져오는 작업을 뜻한다.
들리는 말로는 캐시를 하게 되면 가볍고 속도가 빠르다고 한다.
하지만 휘발성이라 데이터가 안전하지 못한다는 단점을 가지고 있다.
결국 빠른 속도로 데이터를 불러와서 안정적인 서비스를 제공하는것이 목적으로 여겨진다.
그렇담 어떤 데이터를 캐시로 만드는것이 좋을까?
위에서 작성했던 칼럼을 다시 한번 가져와보자.
p.id,
p.brand_id,
b.name,
p.name,
p.price,
p.description,
ps.like_count대략적으로 3개의 테이블로 구분지을수 있다.
1. 상품
2. 브랜드
3. 좋아요 수 (상품 상태)
캐싱을 해야 하는 데이터로는 자주 바뀌지는 않지만 자주 노출이 되어지는 데이터가 좋다고 한다.
왜냐하면 사용자들에게 빠르게 보여줘야 하고,
자주 변하지 않기 때문에 다른곳(?)에 저장해도 크게 상관없다.
고민한 결과..
좋아요 순위 탑 10을 캐싱하기로 결정하였다.
그전에
캐시 전략
전략을 알기전에 사전지식 2가지를 알아야 한다고 한다.
- 캐시 히트 : 캐시 스토어에 데이터가 있는 경우 데이터를 가져옴 (빠름)
- 캐시 미스 : 캐시 스토어에 데이터가 없는 경우 어쩔 수 없이 DB에서 데이터를 가져옴 (느림)
읽기 전략
- Look aside
- cache aside라고 불린다.
- 데이터를 찾을때 우선적으로 저장된 데이터를 캐시에서 찾는 방법 -> 없으면 DB에서 찾음
- read through
- 캐시에서만 데이터를 읽어오는 전략
- 캐시에 데이터가 있으면 바로 반환하고, 없으면 데이터베이스에서 데이터를 로드하여 캐시에 저장한 뒤 애플리케이션에 반환
쓰기 전략
- write back
- 배치 작업을 통해 DB에 반영
- 데이터를 쓸 때 캐시에만 먼저 저장한 뒤, 특정 시간이나 조건이 충족되면 배치(batch) 작업으로 데이터베이스에 한 번에 반영
- 유실 문제가 있음
- write throgh
- 데이터를 캐시와 DB 둘다 반영
- 데이터 일관성 보장
- 쓰기 작업이 두번 발생하기 때문에 굉장히 느림
- write around
- 모든 데이터는 DB에 저장
- 자주 읽히지만 자주 업데이트되지 않는 데이터의 경우, 캐시에 불필요한 데이터가 쌓이는 것을 방지할 수 있음
대략적으로 캐시전략에 대해 알아봤다.
사실 데이터를 캐시로 만들기전에 어떤걸로 캐시를 만들 수 있는지 부터 생각해봐야 한다.
여러가지 방법이 있겠지만 여기에서는 레디스로 캐시를 사용할 예정이다.
그리고 어디에 캐시를 사용할지도 고민하는것이 더 중요하는듯 싶다.
전략 선택하기
위에서 확인했듯이 다양한 전략들이 존재했다.
나는 cache aside방법으로 진행해볼 예정이다.
그 이유는 안정적이면서, 빠르게 적용해볼 수 있는 전략이라 생각했기 때문이다.
코드를 만들고 최초로 등록하였다.
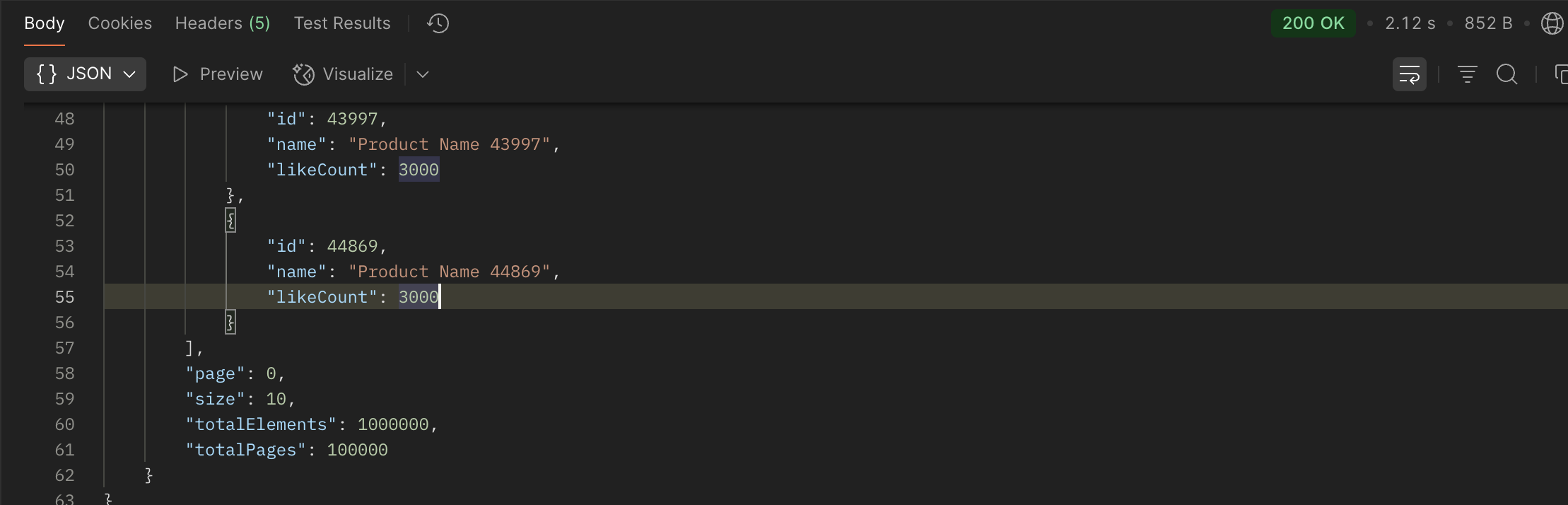
2s가 걸렸다.
분명 캐시를 사용하는걸로 코드를 짰는데 캐시를 이용하지 않고 DB를 이용하게 되어진다.
이런 현상을 없애기 위해서는
warm up
warm up이라는 과정을 거쳐야 한다.
직역하자면, 따뜻하게 해주는 작업이라는건데 쉽게 말해서 데이터를 미리미리 캐시에 넣어주는 행위를 뜻한다.
그렇게 되면 캐시를 사용하게 되니 속도가 빨라지지 않을까?

데이터가 잘 들어간것을 확인 할 수 있었다.
결국 좋아요 순으로 설정해서 탑 10을 캐싱하기로 결정하였다.

api는 무시무시하게 빨라졌다.
결과는 어떨까?
█ TOTAL RESULTS
checks_total.......................: 600 9.860291/s
checks_succeeded...................: 100.00% 600 out of 600
checks_failed......................: 0.00% 0 out of 600
✓ status is 200
HTTP
http_req_duration.......................................................: avg=11.65ms min=1.95ms med=11.64ms max=56.97ms p(90)=15.66ms p(95)=18.93ms
{ expected_response:true }............................................: avg=11.65ms min=1.95ms med=11.64ms max=56.97ms p(90)=15.66ms p(95)=18.93ms
http_req_failed.........................................................: 0.00% 0 out of 600
http_reqs...............................................................: 600 9.860291/s
EXECUTION
iteration_duration......................................................: avg=1.01s min=1s med=1.01s max=1.06s p(90)=1.01s p(95)=1.02s
iterations..............................................................: 600 9.860291/s
vus.....................................................................: 10 min=10 max=10
vus_max.................................................................: 10 min=10 max=10
NETWORK
data_received...........................................................: 522 kB 8.6 kB/s
data_sent...............................................................: 82 kB 1.4 kB/s결론
지금까지 인덱스, 반 정규화, 캐시에 따른 속도를 측정해봤다.
이중에서 엄청난 효과를 보여준 것은 반정규화와 인덱스를 함께 적용했을 때와, 특히 캐싱을 적용했을 때였습니다.그 이유는 인덱스만 적용했을 때, 평균 응답 시간은 10.01s에서 7.35s로 단축되어 약 27%의 속도 향상을 확인할 수 있었습니다. 또한 반정규화만 적용했을 때는 5.28s를 기록하며 Baseline 대비 약 47%의 속도 향상을 보여주었습니다.
다만, 반정규화는 쓰기에 특화된 데이터인지, 읽기에 특화된 데이터인지 확인할 필요가 있다고 생각합니다. 좋아요 같은 경우는 제가 생각할 때, 읽기보다는 쓰기에 좀 더 특화되었다고 생각이 듭니다. 그래서 반정규화는 진행하지 않을 예정입니다.
반면에 캐싱은 생각보다 훨씬 압도적인 효과를 보여주었습니다. 이전 단계(1.24s) 대비 약 1.23s가 빨라졌고, 최초 상태(10.01s)와 비교하면 99% 이상 속도가 개선되어 응답 시간이 밀리초(ms) 단위로 줄어들었습니다. 이는 캐싱할 대상의 데이터 양과 무관하게, DB 접근 자체를 없애는 것이 얼마나 효과적인지 깨닫게 된 계기가 되었습니다. 어떤 데이터를 캐싱하냐에 따라 결과가 극적으로 달라진다는 것을 알 수 있었던 테스트였습니다
| 단계 | 평균 응답 시간 (avg) | p(90) 응답 시간 | p(95) 응답 시간 | TPS (req/s) | 성능 순위 🏆 |
| Baseline (최적화 없음) | 10.01s | 11.67s | 11.70s | 0.9 | 5 |
| 인덱스 적용 | 7.35s | 7.74s | 7.74s | 1.2 | 4 |
| 반정규화 | 5.28s | 5.32s | 5.81s | 1.59 | 3 |
| 반정규화 + 인덱스 | 1.24s | 1.30s | 1.32s | 4.45 | 2 |
| 캐싱 적용 | 0.012s | 0.016s | 0.019s | 9.86 | 1 |
인덱스는 브랜드 + 좋아요 복합인덱스다.
또한, 어떤것을 인덱스로 만들면 좋을지 계속 고민을 했던거 같은데 인덱스를 설정하는게 쉽지 않다는것을 느꼈습니다.
나중에 알게된건데 내가 작업한 인덱스에는 아직도 해결하지 못한 과제가 섞여있다고 하더라구요.ㅜㅜ
몇번이나 수정하고 또 수정했지만 생각만큼 쉽지 않은거 같습니다.
출처
https://khdscor.tistory.com/51
https://mangkyu.tistory.com/69
https://inpa.tistory.com/entry/REDIS-%F0%9F%93%9A-%EC%BA%90%EC%8B%9CCache-%EC%84%A4%EA%B3%84-%EC%A0%84%EB%9E%B5-%EC%A7%80%EC%B9%A8-%EC%B4%9D%EC%A0%95%EB%A6%AC
'개발 > 읽기 성능 개선' 카테고리의 다른 글
| 인덱스 인덱스~~ (1) | 2025.12.08 |
|---|---|
| 인덱스 혼자 끄적이기 (2) | 2025.08.17 |
| 기존 테스트.. (4) | 2025.08.15 |