batch - step,job
- 개발
- 2026. 4. 10. 23:05
배치의 전반적인 처리 과정에 대해 학습을 진행하였다. 배치는 기본적으로 3가지 단계로 동작한다.
Reader → Processor → Writer데이터를 읽고, 가공하고, 저장하는 구조이다.
하지만 현재까지는 이 흐름을 단순하게 확인하기 위해 배치를 강제로 실행시키는 방식으로 동작을 확인하고 있었다.

즉, 배치의 구조를 제대로 사용하기보다는 동작 자체를 이해하는 데에 초점을 맞춘 상태였다. 하지만 스프링 배치에서는 이러한 작업 흐름을
Job과 Step이라는 개념을 통해 구조적으로 관리할 수 있다. 단순 실행에서 벗어나, 실행 단위와 흐름을 명확하게 정의할 수 있는 것이다.
그렇다면 스프링 배치에서는 이 Job과 Step을 어떻게 구성하고 사용하는지 확인해보자. 그리고 저번시간에 재대로 설명하지 않은 chunk도 함께 알아보자.
그렇다면, Step이란 무엇일까?
사실 지금까지 작성했던 코드를 보면 이미 Step과 비슷한 구조로 동작하고 있었다.
Reader → Processor → Writer 흐름을 직접 이어서 실행하고 있었기 때문이다.
즉, 위에서 보였던 코드는 Step을 "흉내낸 코드"라고 볼 수 있다.
하지만 스프링 배치에서의 Step은 단순히 흐름을 묶는 수준이 아니다.
Step은 배치 처리의 "실행 단위"이다. Reader, Processor, Writer를 하나로 묶어서 실제로 동작시키는 역할을 한다.
조금 더 정확하게 말하면 Step은 다음과 같은 것들을 관리한다.
- Reader → Processor → Writer 흐름 실행
- 트랜잭션 관리
- 반복 처리 (chunk 기반 처리)
- 실패 시 재시도 및 롤백
즉, 우리가 직접 구현했던 단순한 흐름에 "운영에 필요한 기능"이 추가된 구조라고 보면 된다.
그래서 이전까지는 "동작을 이해하기 위해 직접 연결해서 실행했다"라면
이제부터는 "스프링 배치가 제공하는 Step을 통해 구조적으로 실행한다"라고 보면 된다.

그렇다면, Step이 많아지면 어떻게 되어질까?
답은 생각보다 단순하다. 여러 개의 Step을 하나로 묶어서 관리하게 된다.
이때 등장하는 개념이 바로 Job이다. Job은 여러 개의 Step을 하나의 흐름으로 구성한 상위 개념이다.
즉, Step이 하나의 작업 단위라면 Job은 그 작업들을 순서대로 실행하는 "전체 흐름"이라고 보면 된다.
예를 들어, 다음과 같은 상황을 생각해볼 수 있다.
- Step1: 데이터 조회
- Step2: 데이터 가공
- Step3: 데이터 저장
이렇게 여러 개의 Step이 존재할 경우, 이 Step들을 순서대로 실행하도록 묶어주는 것이 바로 Job이다.
즉 구조를 정리하면 다음과 같다.
Job → Step → (Reader → Processor → Writer)이렇게 계층 구조로 이루어져 있다. 결국 Step이 하나일 때는 단순한 배치 작업이지만,
Step이 여러 개가 되면 하나의 흐름으로 관리해야 할 필요가 생기고 그 역할을 Job이 담당하게 된다.
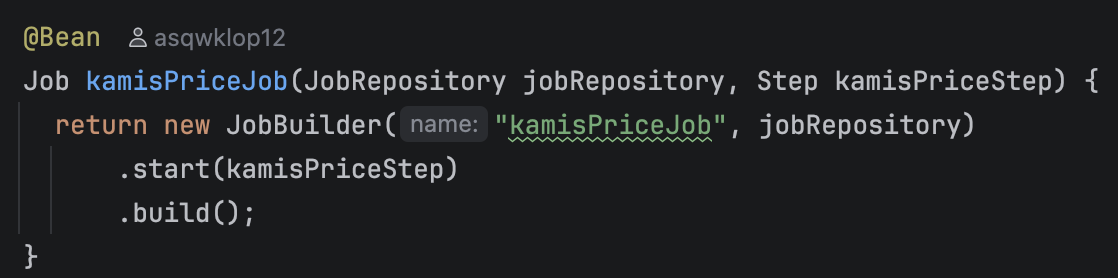
현재는 배치의 모든 과정을 하나의 Step으로 만들었기때문에 Job에 들어가는 Step하나 뿐이다.
JobOperator
아무리 Job과 Step을 잘 나누어두었다고 하더라도, 결국 이것을 실제로 실행시켜줄 실행기가 필요하다.
물론 처음 보여줬던 코드처럼 직접 호출하는 방식으로 작성할 수도 있다. 동작만 놓고 보면 그렇게 작성해도 큰 문제는 없다.
하지만 여기에는 중요한 차이점이 존재한다. 바로 스프링이 관리하는 코드인가, 아닌가 하는 점이다.
처음 방식은 개발자가 직접 실행 흐름을 제어하는 구조이다. 즉, 스프링 배치의 실행 구조 안에서 동작하는 것이 아니라,
우리가 강제로 호출해서 실행시키는 코드라고 볼 수 있다.
다시 말해, 이 코드는 스프링이 관리하는 배치 코드라기보다는, 배치와 비슷한 흐름을 직접 구현한 코드에 가깝다.
반면 스프링 배치에서는 JobOperator와 같은 실행 구조를 통해
스프링이 Job을 인식하고, 정해진 방식에 따라 실행하고 관리할 수 있도록 한다.
즉 핵심은 단순하다.
직접 실행하는 방식은 "배치처럼 보이는 코드"이고, 스프링이 관리하는 방식은 "실제로 스프링 배치 위에서 동작하는 코드"이다.

Chunk
Chunk는 데이터를 일정 단위로 끊어서 처리하는 역할을 한다.
한 번에 너무 많은 데이터가 들어오게 되면, 처리 중 실패할 가능성이 높아진다.
그래서 배치에서는 데이터를 일정 크기로 나누어 처리하는 방식을 사용한다.
예를 들어 10,000개의 데이터를 한 번에 저장하는 것보다, 100개씩 나누어 100번 저장하는 방식이 더 안정적 일 수 있다.
이렇게 하면 중간에 실패하더라도 전체가 아닌 일부만 다시 처리하면 되기 때문에, 복구와 재처리 측면에서도 유리하다.
배치에 대해 기본적으로 학습해야 하는 부분은 완료가 되어졌다고 느껴진다. 하지만 이것보다 깊게 들어가는 작업은 아직 진행하지는 않았습니다. 예를 들면, 기존에는 JobLaucher이 존재하였습니다. 하지만 spring 6.0이후부터는 JobOperator를 사용하도록 권장하고 있습니다. 어째서 JobLauncher는 더 이상 사용하지 않는지, 두 개의 차이점은 무엇이며, JobOperator의 장점이 어떤게 있는지 상세하게 파볼 예정입니다. 또, 현재는 스케쥴방식이 아닌 수동으로 배치를 돌리고 있습니다. 스케쥴 방식으로 바꾸게 되면 어떤 문제가 있는지도 살펴보면 좋을거 같네요. 다음 배치는 조금더 깊게 들어가는 시간을 가져보겠습니다. 긴 글 읽어주셔서 감사합니다.
'개발' 카테고리의 다른 글
| 웹소켓 vs mq (0) | 2026.04.20 |
|---|---|
| race condition (0) | 2026.04.13 |
| Batch - processor, writer (0) | 2026.04.09 |
| 카프카의 설정은 진짜일까?? - offset(1) (0) | 2026.04.08 |
| Batch- Reader (0) | 2026.04.07 |