race condition
- 개발
- 2026. 4. 13. 21:47
Race condition은 여러 작업이 동시에 같은 데이터를 처리할 때, 실행 순서에 따라 결과가 달라지는 문제입니다.
쉽게 말해, 같은 자원에 대한 접근이 동시에 발생하면서 기대한 결과와 실제 결과가 달라지는 상황입니다.
이전 선착순 쿠폰 시스템을 개발할 때도 이러한 문제가 발생했습니다.

예를 들어 100명의 사용자가 동시에 쿠폰 발급을 요청했다고 가정하겠습니다. 응답 결과만 보면 6건만 성공했고, 94건은 실패했습니다.
그렇다면 정상적인 시스템이라면 실제 DB에도 성공한 6건만 저장되어 있어야 합니다.
하지만 실제로 확인해보니 DB에는 96건의 쿠폰 발급 내역이 저장되어 있었습니다.
즉, 애플리케이션이 사용자에게 반환한 결과와 실제 데이터베이스 상태가 서로 일치하지 않았습니다.
이런 상황을 정합성이 깨졌다고 할 수 있습니다. 더 정확하게는, 동시성 문제로 인해 데이터 정합성이 깨진 상태라고 표현할 수 있습니다.
반대로, 응답 결과가 6건 성공, 94건 실패이고 실제 DB에도 정확히 6건만 저장되었다면, 비록 실패 요청이 많았더라도 정합성은 유지된 것입니다. 즉, 정합성은 단순히 성공이나 실패 수가 많은지가 아니라, 시스템이 기대한 결과와 실제 저장된 데이터가 일치하는지로 판단해야 합니다.
이처럼 race condition은 단순히 일부 요청이 실패하는 문제를 넘어, 성공/실패 응답과 실제 데이터 상태를 어긋나게 만들어 시스템 신뢰성을 무너뜨릴 수 있습니다. 그렇다면 이제 중요한 질문은 하나입니다. 이 race condition을 어떻게 제어하고, 데이터 정합성을 어떻게 보장할 것인가입니다.
race condtion이 왜 발생하는지 생각해봅시다.
위에서 동시성 문제로 인해 race condition이 발생한다고 설명했습니다.
그렇다면 race condition이란 무엇일까요?
다음 그림을 보면 여러 요청이 동시에 동일한 자원에 접근하고 수정하는 상황을 확인할 수 있습니다.
이때 각 요청은 독립적으로 처리되기 때문에 실행 순서가 보장되지 않습니다.
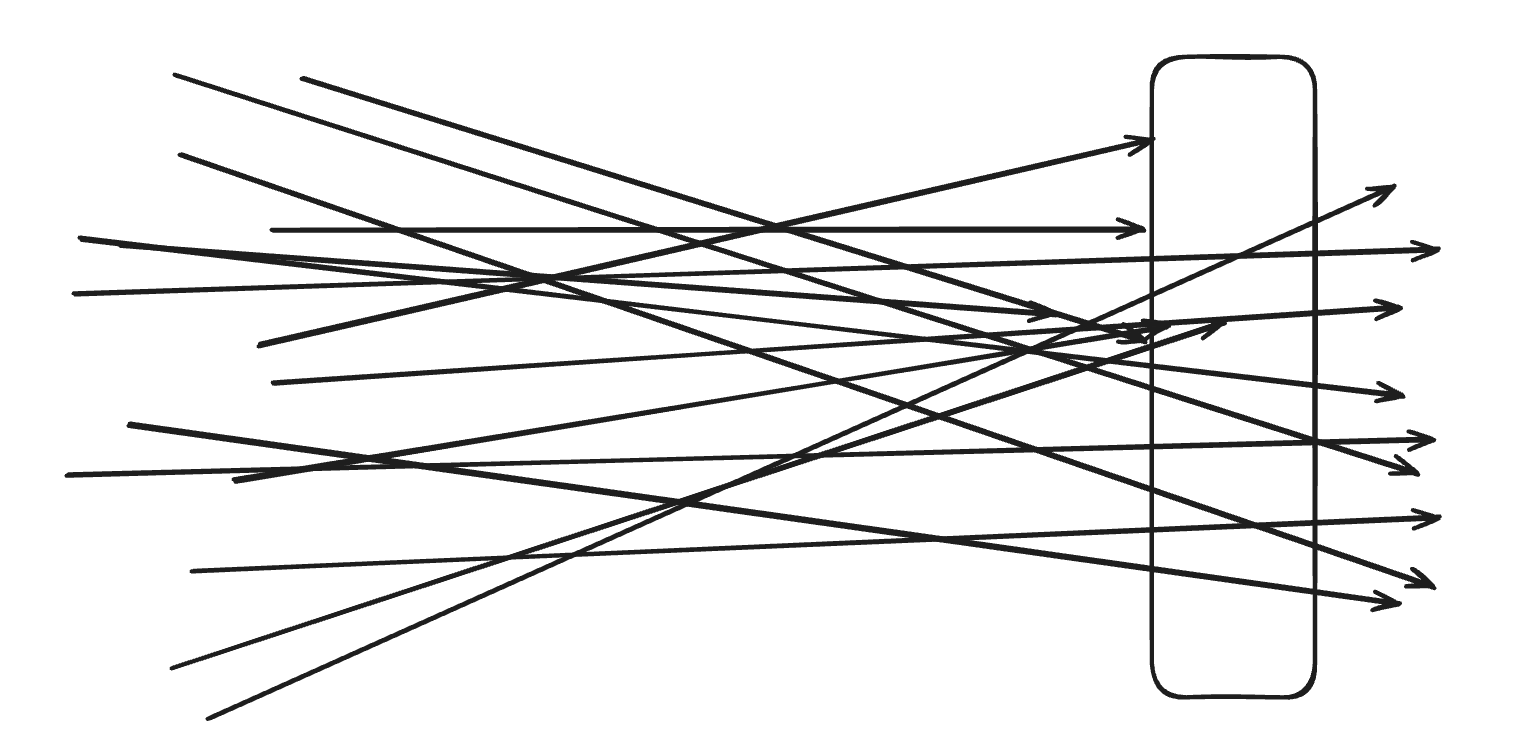
그 결과 다음과 같은 문제가 발생할 수 있습니다.
- 중복 발급
- 데이터 불일치
- 응답 결과와 DB 상태 불일치
즉, 여러 요청이 서로의 상태를 고려하지 않은 채 동시에 실행되면서 예상하지 못한 결과가 발생하는 것이 바로 race condition입니다.
race condition이라는 용어는 말 그대로 경주(race)에서 유래했습니다.
여러 요청이 동시에 자원에 접근하면서 누가 먼저 실행될지 알 수 없는 상태,
즉 제어되지 않은 경쟁 상황을 의미합니다.
여기서 알 수 있는 정보는 하나입니다. 실행 순서가 보장이 되지 않는 점입니다.
그렇다면, 순서를 보장하기 위해서는 어떻게 할 수 있을까요?
순서를 보장하기 위해서는 어떻게 할 수 있을까?
핵심은 단순합니다. 여러 요청이 동시에 같은 자원을 수정하지 못하도록 만들어야 합니다.
동시에 같은 자원을 수정하지 못하게 만들려면 어떻게 해야 할까요?
Lock을 건다
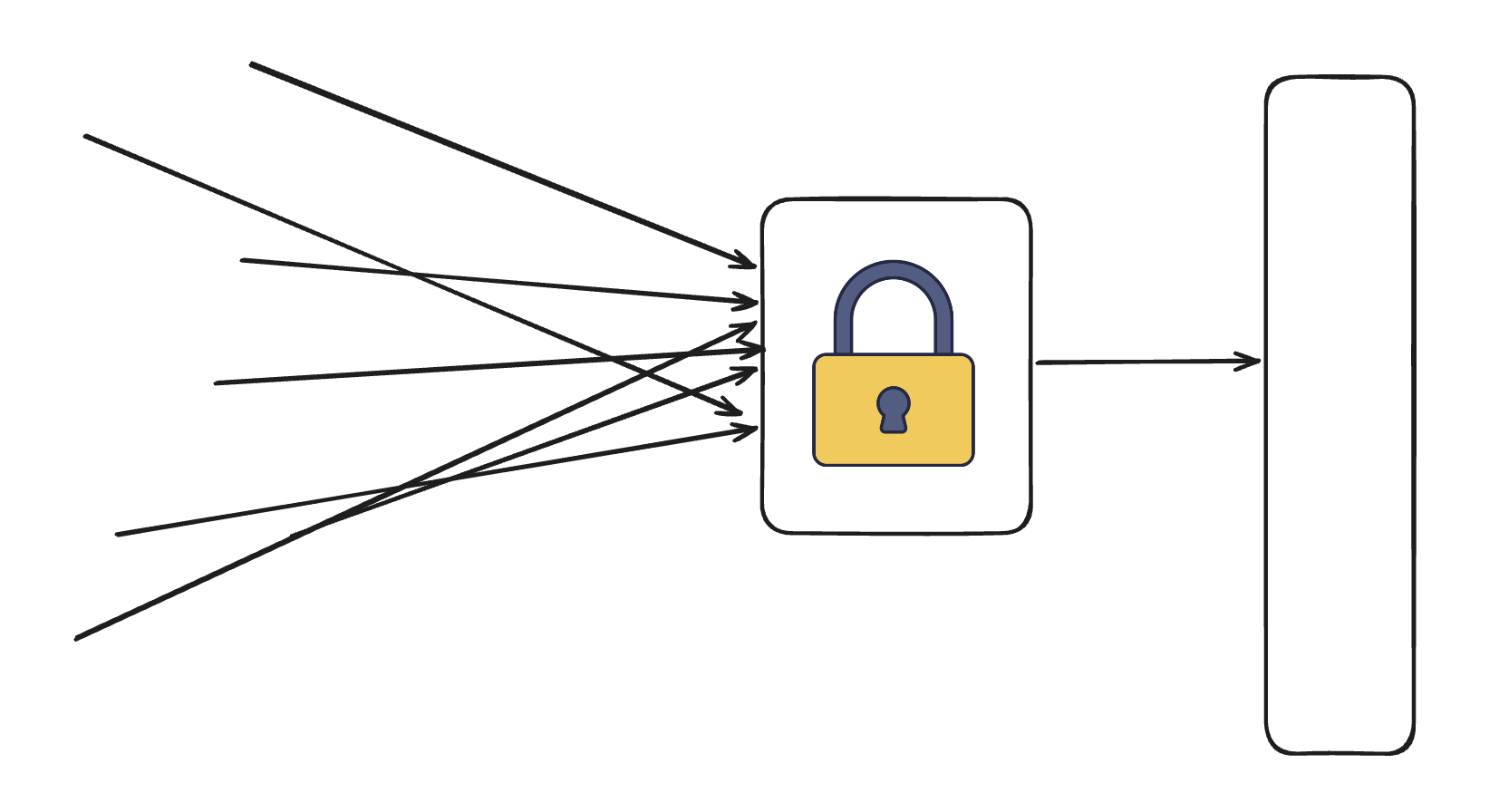
락을 사용하게 되면 동시에 하나의 요청만 자원에 접근할 수 있도록 제어할 수 있습니다.
즉, 하나의 요청이 작업을 수행하는 동안 다른 요청들은 대기하게 됩니다.
이러한 방식은 race condition을 방지하고 데이터 정합성을 보장하는 데 효과적입니다.
하지만 동시에 처리할 수 있는 요청 수가 제한되기 때문에,
대기 시간이 발생하며 전체적인 응답 지연(latency)이 증가할 수 있습니다.
대표적인 방법은, synchronized, DB Lock, 분산 락등이 있습니다.
범위를 줄인다

범위를 줄이는 방법은 lock을 사용하는 방식에 비해 근본적인 해결책은 아닙니다. 범위를 줄인다는 것은 동일한 자원에 대한 접근 빈도를 낮추는 것이지, 동시에 접근이 발생하는 상황 자체를 제거하는 것은 아니기 때문입니다.
예를 들어 처리 대상이 100만 건에서 1000건으로 줄어들었다고 하더라도, 여전히 여러 요청이 동시에 같은 자원에 접근할 수 있으며,
race condition이 발생하지 않는다는 보장은 없습니다.
다만 이 방식은 추가적인 락이나 큐를 사용하지 않기 때문에, 자원 사용 측면에서는 가장 부담이 적은 접근입니다.
따라서 race condition이 치명적이지 않거나, 충돌 가능성을 낮추는 것만으로도 충분한 경우라면
범위를 줄이는 방식부터 적용하는 것이 효과적인 선택이 될 수 있습니다.
큐를 이용해서 순차화를 시킨다
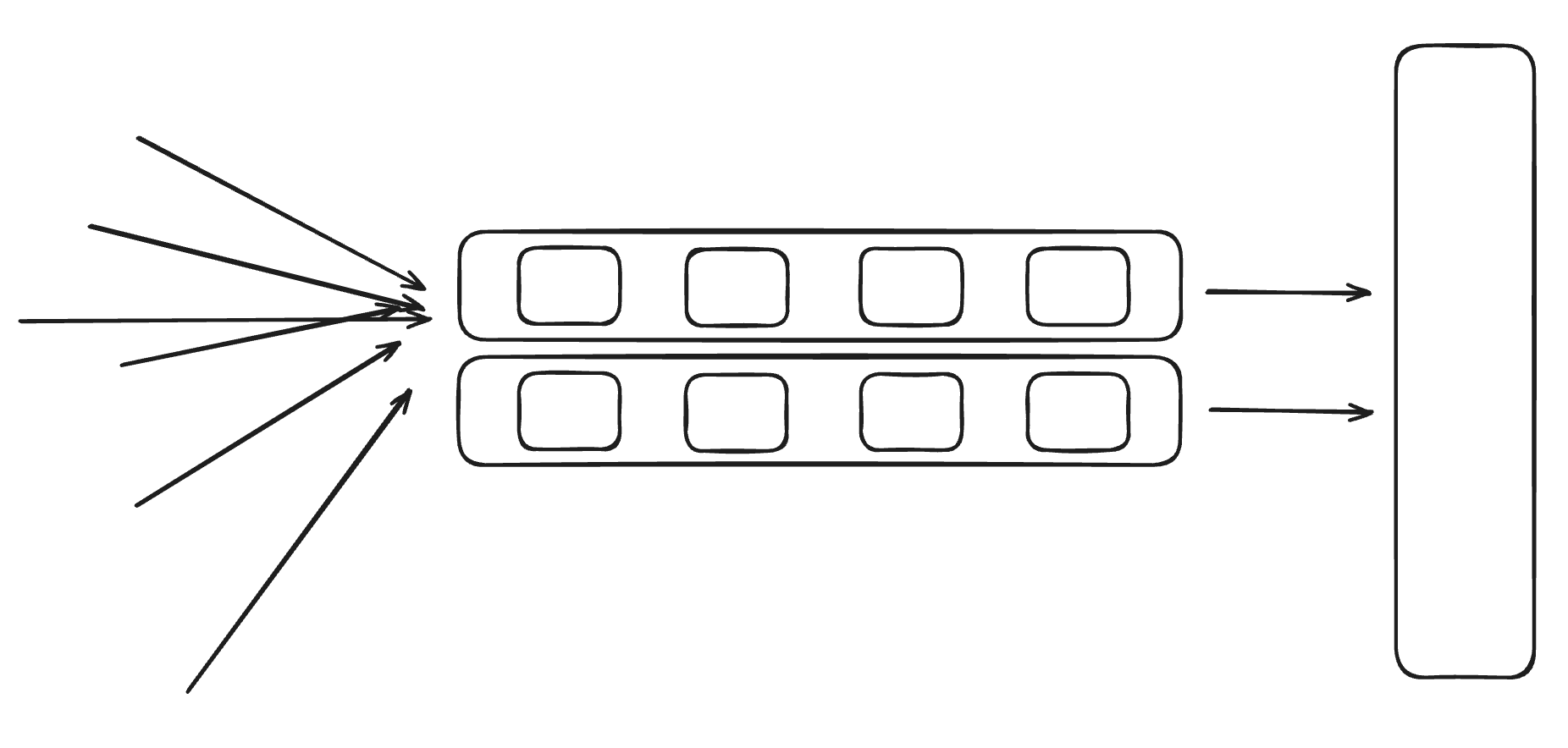
락을 사용하는 방법이나 범위를 줄이는 방법과 비교하면, 큐를 사용하는 방식도 비슷한 해결책처럼 보일 수 있습니다.
이 점은 부정하지 않겠습니다.
하지만 큐를 사용하는 방식의 본질은 다릅니다. 요청과 실제 처리를 분리하는 구조라는 점입니다.
요청을 받는 시점에는 단순히 큐에 적재만 하고, 실제 처리는 이후에 별도의 consumer가 수행하게 됩니다.
즉, 요청 처리 경로에서 무거운 작업을 제거할 수 있고, 그 결과 사용자 입장에서는 더 빠르게 응답을 받을 수 있습니다.
또한 큐를 사용하면 다음과 같은 장점을 얻을 수 있습니다.
첫 번째는 처리 흐름을 제어할 수 있다는 점입니다. 단일 consumer를 사용한다면 요청을 순차적으로 처리할 수 있고,
동시에 접근하면서 발생하는 race condition을 줄일 수 있습니다.
두 번째는 확장성입니다. 큐는 여러 개의 consumer를 통해 병렬 처리가 가능하기 때문에, 트래픽이 증가하더라도 유연하게 대응할 수 있습니다.
하지만 이 구조에도 중요한 함정이 존재합니다.
첫 번째는 큐에 들어가기 전 단계에서 race condition이 발생할 수 있다는 점입니다.
즉, 큐에 넣기 전에 이미 공유 자원을 조회하거나 검증하는 로직이 있다면, 여전히 동시성 문제가 발생할 수 있습니다.
두 번째는 병렬 처리로 인한 race condition입니다. 여러 consumer를 사용해 병렬로 처리할 경우, 다시 동시에 같은 자원을 수정하는 상황이 발생할 수 있습니다. 이 경우 latency는 개선될 수 있지만, 정합성 문제가 다시 나타날 수 있습니다.
따라서 큐 기반 구조는 단순히 도입하는 것만으로는 충분하지 않고, 큐에 들어가기 전 단계와 consumer 처리 단계 모두에서
동시성 제어를 함께 고려해야 합니다.
이 두 가지 문제를 함께 해결할 수 있다면, 락 기반 방식이나 단순 범위 축소 방식보다 더 높은 성능과 정합성을 동시에 확보할 수 있는 구조라고 생각합니다.
앞에서 설명한 여러 방법을 적용하더라도, 모든 상황에서 race condition을 완벽하게 제거할 수 있다고 보기는 어렵습니다. 중요한 것은 race condition을 무조건 없애는 것 자체보다, 어떤 구간에서 동시성 문제가 발생할 수 있는지를 인지하고, 그에 맞는 방법으로 제어하는 것이라고 생각합니다. 즉, 핵심은 race condition의 가능성을 이해하고, 문제가 발생할 수 있는 지점을 찾은 뒤, 락, 큐, 조건부 갱신, 범위 분산과 같은 적절한 방법을 상황에 맞게 적용하는 것입니다. 결국 실무에서 중요한 것은 동시성 문제를 완벽하게 통제할 수 있다고 믿는 것이 아니라, 문제가 발생할 수 있음을 전제로 설계하고 대응하는 것이라고 생각합니다.
선착순 쿠폰 시스템을 개발하면서 2가지 문제가 발견이 되었습니다. 그 중 하나를 다음 시간에 적용해볼려고 합니다.

10000장의 쿠폰을 대상으로 500명의 동시 요청을 발생시키는 테스트를 진행했습니다. 그 결과, 일부 요청에서 총 63건의 실패가 발생했습니다. 이 시점에서는 큐를 통해 처리하기 이전 단계였기 때문에, HTTP 요청을 처리하는 과정에서 동시 접근이 발생했고,
그로 인해 race condition이 발생했을 가능성이 높다고 판단했습니다. 이를 해결하기 위해, 요청 처리 구조를 다시 점검해보았습니다.
'개발' 카테고리의 다른 글
| 카프카의 설정은 진짜일까?? - offset(2) (0) | 2026.04.22 |
|---|---|
| 웹소켓 vs mq (0) | 2026.04.20 |
| batch - step,job (0) | 2026.04.10 |
| Batch - processor, writer (0) | 2026.04.09 |
| 카프카의 설정은 진짜일까?? - offset(1) (0) | 2026.04.08 |